New AI is amazing at depixelating images — but it also highlights the problem of data bias
Andrei Mihai
It’s almost become a cliche for AI stories, but this new algorithm does a brilliant job of highlighting it: the technology is exciting and remarkable, but far from mature and robust — and data bias can be an issue.

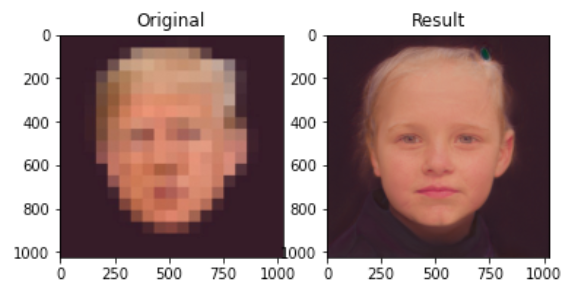
The algorithm, called PULSE, attempts to produce high-resolution images from pixelated portraits. It’s not the first time algorithms have been developed for the purpose of de-pixelating images, but PULSE does it a bit differently: it’s not ‘zoom and enhance’, it’s entirely another approach.
Instead of trying to see what colors would fit in each pixel, the algorithm actually produces new, original faces. PULSE is essentially a GAN — a Generative Adversarial Network, in which two different algorithms work in an adversarial fashion. In this context, one algorithm would produce an original face not belonging to any human, and the other algorithm tries to find differences between the pixelated image and the generated face.
In recent times, advances in this field have surged. You need only visit This Person Does Not Exist and click refresh several times — you’ll see just how eerily realistic these AI-generated faces can be. PULSE uses a somewhat similar approach, except it also compares the generated images with the pixelated image to produce a plausible, realistic portrait.
Even when facial features are barely recognizable, “our algorithm still manages to do something with it, which is something that traditional approaches can’t do,” said co-author Alex Damian ’20, a Duke math major.

However, there’s a catch: none of these faces are real. In other words, what the algorithm is producing isn’t a high-resolution version of the pixelated image, it’s a brand-new face that fits with the input data.
This means that it can’t, and shouldn’t be used for something like facial recognition or crime scene investigation. Instead, researchers say it could be used to complement satellite imagery and medical imaging, as well as microscopy and astronomy.
You can see the results for yourself here or by checking the published paper at arXiv. You can also check out the AI and use it yourself via GitHub, and this is where things get even more interesting.
As expected, when you expose an AI to the online world, people start testing and experimenting with it.

First, one of the study authors themselves played with the AI, generating a human image of the famous game character B.J. Blazkowicz, who starred in the famous Wolfenstein games. For millions of old-school gamers, it was a chance to see how the protagonist of several cult classics may have looked like in reality. It’s hard to imagine that a man like B.J. Blazkowicz could exist in reality, but if he did, that’s probably what he would have looked like.
But then, other people came across something weird. In some cases, the algorithm behaved weirdly. Here’s an example of the type of unexpected result:

Most people would look at the left picture and they’d see a pixelated photo of former US President Barack Obama. Yet, the image on the right looks nothing like Obama.
As mentioned, the faces don’t belong to an actual person so it was bound to generate some differences, but this is more than an isolated example: it’s a trend, Twitter users found.
Here’s another example, depicting a pixelated an unpixelated image of US Congresswoman Alexandria Ocasio-Cortez.

Twitter user Robert Osazuwa Ness posted another example, of his wife:

… and another one of actress Lucy Liu:

By now, you probably see the trend: the AI appears to have a bias in how it depixelates faces. Obviously the AI has no opinion or biases, so what’s going on?
The problem with any AI, or any data project really, is that it’s only as good as its input data. If you want to make good wine, you need good grapes, and finding the right grapes is challenging.
This is probably what’s happening here: the algorithm was trained with a specific dataset, and if most people in that dataset tend to look in a specific way, the AI is more inclined to generate images that fit these trends.
This data bias is an artifact of the dataset, and the authors themselves did not appear fully aware of it until it was pointed out.
“It does appear that PULSE is producing white faces much more frequently than faces of people of color,” wrote the algorithm’s creators on Github. “This bias is likely inherited from the dataset […] though there could be other factors that we are unaware of.”
At this point, it’s still too soon whether this is a shortcoming of the algorithm itself or an artifact of the training data, but the problem is surprisingly widespread in machine learning.
It’s actually a well-known problem in facial recognition: algorithms often work worse on non-white people. It’s not entirely clear why this happens, but an often-quoted NIST report found that even the best algorithms still struggle with this.
Data bias can be a major pitfall of machine learning, and it’s an issue that researchers need to be aware of, both for socially and technical reasons. These are just a few (potentially isolated) examples of bias, but there can be many more problem
Of course, the algorithm itself isn’t perfect, and could also be improved upon.
But in the grand scheme of things, it’s more important than ever to be aware of this bias and address it. This is an interesting and important study, highlighting both the potential and the shortcomings of current machine learning.
We’re experiencing an advent of AI, and while still in its infancy, the technology is taking major strides, so the earlier we can set it on a healthy course, the better.
The post New AI is amazing at depixelating images — but it also highlights the problem of data bias originally appeared on the HLFF SciLogs blog.